java并发系列-线程池,简单介绍线程池的几种实现方式,以及如何动态设置线程池参数。
线程池简介
线程池是一种基于池化思想管理线程的工具,经常出现在多线程服务器中。
线程池可以看作是线程的集合,在没有任务时,线程处于空闲状态,当请求来时,线程池给这个请求分配一个空闲的线程,任务完成后,回到线程池中等待下次任务。
使用线程池优点
- 降低资源消耗:通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。
- 提高相应速度:当任务到达时,任务不需要等到线程创建就能立即执行。
- 提高线程的可管理性:线程时稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
Executor框架
JDK给我们提供了Excutor框架,来使用线程池,Ex cutor是线程池的基础。Executor提供了一种将任务提交与任务执行分离开来的机制。
jdk线程池的总体api架构:
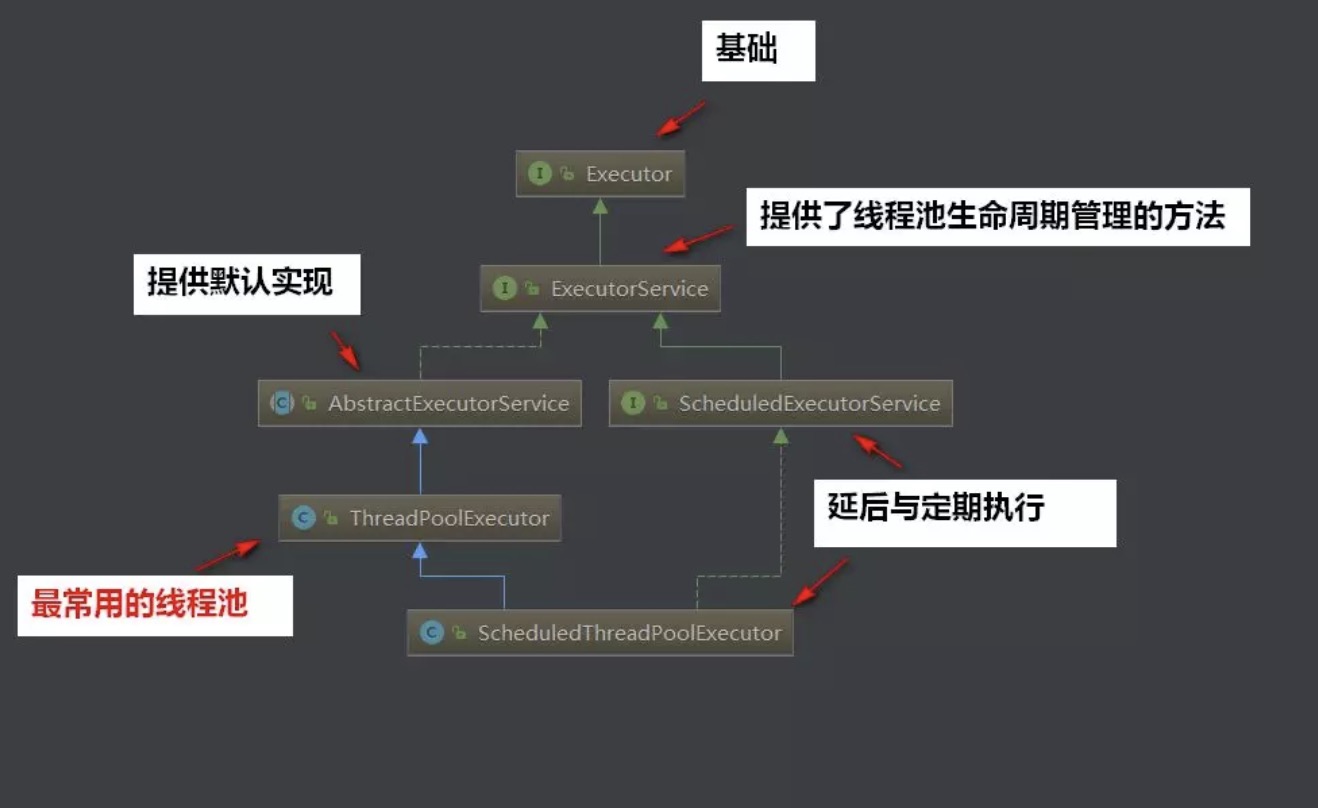
Executor组成
组成部分
任务(Runnable/Callable)
执行任务需要实现Runnable接口或者Callable接口,Runnable/Callable实现类都可以被ThreadPoolExecutor 或ScheduledThreadPoolExecutor执行。
任务的执行(Executor)
任务执行机制的核心接口Executor,继承自Exector接口的ExecutorService接口,ThreadPoolExecutor和ScheduledThreadPoolExecutor实现了ExecutorService接口。
异步计算结果(Future)
Future接口以及Future接口的实现类FutureTask类都可以代表一步计算的结果。当我们提交Runnable接口或者Callable接口的实现类给ThreadPoolExecutor或者ScheduledThreadPoolExecutor执行,调用Submit方法时会返回一个FutureTask对象。
执行步骤
- 主线程首先要创建实现Runnable或者Callable接口的任务对象。
- 把创建完成的实现Runnable、Callable接口的对象直接交给ExecutorService执行(ExecutorService.execute(Runnable command))或者也可以把Runnable对象、Callable对象提交给ExecutorService执行(ExecutorService.submit(Runnable task) 或者ExecutorService.submit(Callable
task))。 - 如果执行ExecutorService.submit(),ExecutorService将返回一个实现Future接口的对象,(execute()执行没有返回值,submit()会返回一个FutureTask对象),由于FutureTask实现了Runnable,我们也可以创建FutureTask,然后直接交给ExectorService执行。
- 最后,主线程可以执行FutureTask.get()方法来等待任务执行完成,主线程也可以执行FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行。
Executor工具类实现线程池
常见的线程池实现方式有:Executor工具类可以实现三种类型的线程池(newFixedThreadPool、newCachedThreadPool、newSingleThreadExecutor);
newFixedThreadPool
FixedThreadPool被称为可重用固定线程数的线程池,源码实现:
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
从源码可看出,创建的FixedThreadPool的corePoolSize和maximumPoolSize都被设置为nThreads,这个nThreads参数是使用时传入的。
不推荐使用的原因
FixedThreadPool使用无界队列 linkedBlockingQueue,队列的容量为Integer.MAX_VALUE,将对线程池影响:
- 线程池中线程数达到corePoolSize后,先任务将在无界队列中等待,因此线程池中的线程数不会超过corePoolSize
- maximumPoolsize将是一个无效参数,因为不可能存在队列满的情况
- keepAliveTime将是一个无效参数
- 运行中的FixedThreadPool不会拒绝任务,在任务比较多的时候会导致OOM内存溢出
newSingleThreadExecutor
SingleThreadExecutor是只有一个线程的线程池,源码实现:
1 | public static ExecutorService newSingleThreadExecutor() { |
从源码可以看出,新创建的SingleThreadExecutor的corePoolSize和maximumPoolSize都设置成了1,其他参数和FixedThreadPool相同,也即SingleThreadPool是nThreads=1时的FixedThreadPool。
不推荐使用的原因
由于SingleThreadPool是nThreads=1时的FixedThreadPool,所以原因和FixedThreadPool的原因相同,主要问题是会导致OOM。
newCachedThreadPool
CachedThreadPool是一个根据需要创建新的线程的线程池,源码实现:
1 | public static ExecutorService newCachedThreadPool() { |
根据源码,CachedThreadPool的corePoolSize被设置为0,maximumPoolSize被设置为无界Integer.MAX_VALUE,这样的话,如果主线程提交任务的速度大于正在处理任务的线程的速度时,cachedThreadPool会不断的创建新的线程,极端情况下,会打导致耗尽CPU和内存资源。
不推荐使用原因
CachedThreadPool允许创建线程数量为Integer.MAX_VALUE,可能会创建大量线程,从而导致OOM。
ThreadPoolExecutor构造方法实现线程池
可以通过ThreadPoolExecutor构造方法实现自定义参数的线程池。
线程池实现类ThreadPoolExecutor是 Executor框架最核心的类,ThreadPoolExecutor类中提供了四个构造方法,我们来看最长的那个,其余三个都是在这个构造方法的基础上产生的,其他几个构造方法说白点,都是给定某些默认参数的构造方法,比如默认制定拒绝策略等等。
构造方法源码
1 | /** |
参数
ThreadPoolExecutor 构造方法的参数(源码注释):
corePoolSize:the number of threads to keep in the pool, even if they are idle, unless {@code allowCoreThreadTimeOut} is set
核心线程数:不管它们创建以后是不是空闲的,线程池需要保持corePoolSize数量的线程,除非设置了allowCoreThreadTimeOut。
maximumPoolSize:the maximum number of threads to allow in the pool。
最大线程数:线程池中最多允许创建maximumPoolSize个线程。
keepAliveTime:when the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating。
存活时间:如果经过keepAliveTime时间后,超过核心线程数的线程还没有接收到新的任务,那就回收。
unit:the time unit for the {@code keepAliveTime} argument
keepAliveTime的时间单位。
workQueue:the queue to use for holding tasks before they are executed. This queue will hold only the {@code Runnable} tasks submitted by the {@code execute} method。
存放待执行任务的队列:当提交的任务数超过核心线程数大小后,在提交的任务就存放在这里,它仅仅用来存放被execute方法提交的Runnable任务。
threadFactory:the factory to use when the executor creates a new thread。
线程工厂:用来创建线程的工厂,比如这里可以定义线程的名称,在进行虚拟机栈分析时,看名字就知道线程来自哪里。
hander:the handler to use when execution is blocked because the thread bounds and queue capacities are reached。
拒绝策略:当队列里面放满了任务,最大线程数的线程都在工作时,这是继续提交的任务线程池就处理不了了,应该按照给定的拒绝策略处理这些线程。
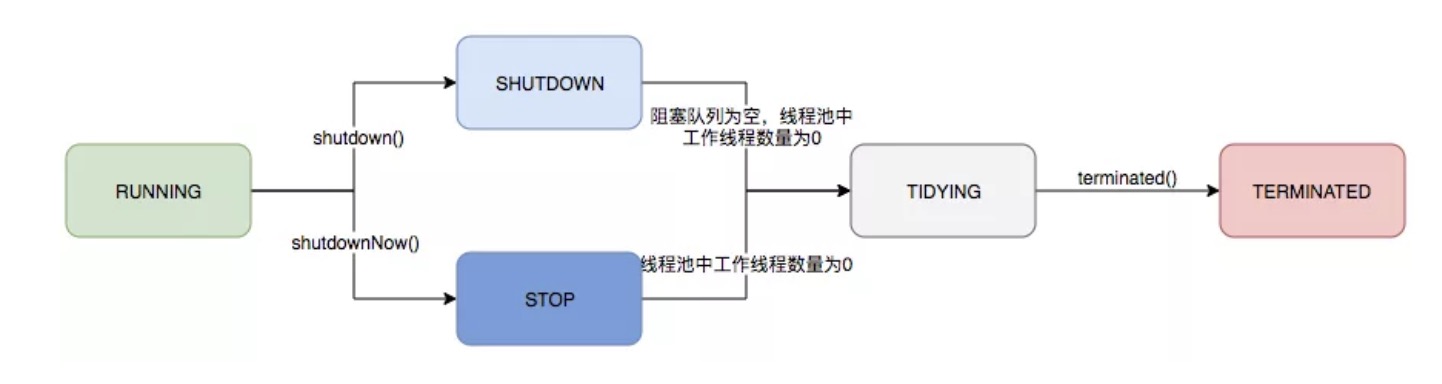
生命周期
线程池内部使用一个变量维护两个值:运行状态runState和线程数量workerCount,具体实现中,线程池将运行状态runState、线程数量workerCount两个参数维护放在了一起
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
ctl 定义为AtomicInteger,记录了线程池中的任务数量,和线程池的状态,两个信息。高3位保存runState,低29位保存workerCount。线程池也提供了若干方法获得线程池的当前运行状态、线程个数,这里使用的是位运算,相比基本运算,速度会快很多。
1 | private static int runStateOf(int c) { return c & ~CAPACITY; } //计算当前运行状态 |
ThreadPoolExecutor的运行状态有5种:
| 运行状态 | 状态描述 |
|---|---|
| RUNNING | 能接受新提交的任务,并且也能处理阻塞队列中的任务。 |
| SHUTDOWN | 关闭状态,不在接受新的提交任务,但却可以继续处理阻塞队列中已保存的任务。 |
| STOP | 不能接受新的任务,也不处理队列中的任务,会中断正在处理任务的线程。 |
| TIDYING | 所有的任务都已经终止了,workerCount有效线程数为0。 |
| TERMINATED | 在terminated()方法执行完后进入改状态。 |
生命周期转换如下:
线程执行流程
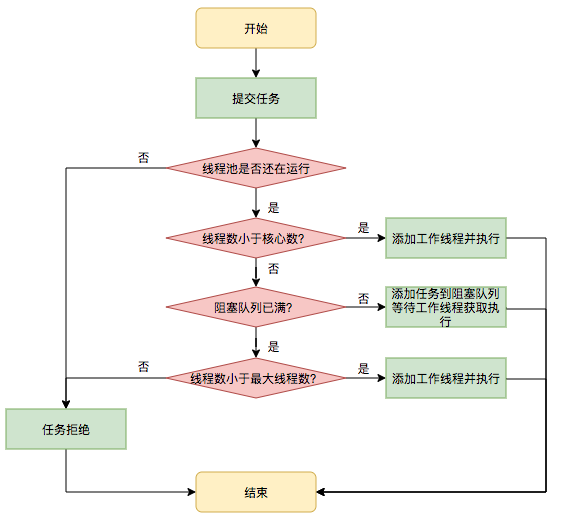
所有任务调度都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请或者直接拒绝。执行过程如下:
- 首先检测线程池运训状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING状态下执行任务。
- 如果workerCount < corePoolSize,则创建并起动一个线程来执行新提交的任务。
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞对了中。
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= maximumPoolSize ,并且线程池内的阻塞队列已满,则根据拒绝策略来处理该任务,默认处理方式是直接抛异常。
流程图:
任务阻塞
使用不同的队列可以实现不同热任务存取策略,常用的阻塞队列有:
| 名称 | 描述 |
|---|---|
| ArrayBlockingQueue | 一个用数组实现的有界阻塞队列,此队列按照先进先出FIFO的原则对元素进行排序,支持公平锁和非公平锁。 |
| LinkedBlockingQueue | 一个由链表结构组成的有界队列,此队列按照先进先出FIFO的原则对元素进行排序,此队列默认长度为Integer.MAX_VALUE,所以默认创建的队列有容量危险。 |
| PriorityBlockingQueue | 一个支持线程优先级排序的无界队列,默认自然序进行排序,也可以自定义compareTo方法来指定排序规则,不能保证同优先级元素的顺序。 |
| DelayQueue | 一个实现PriorityBlickingQueue实现延迟获取的无界队列,在创建元素时,可以指定多久才能从队列中获取当前元素,只有延时期满后才能从队列中获取元素。 |
| SynchronousQueue | 一个不储存元素的阻塞队列,每一个put操作必须等待taker操作,否则不能添加元素,支持公平锁和非公平锁,SynchronousQueue的一个使用场景时在线程池里,Executors.newCachedThreadPool()就使用了这个队列,这个线程池根据需要,新任务到来时,创建线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。 |
| LinedTransferQueue | 一个由链表结构组成的无界阻塞队列,相当于其他队列,LinedTransferQueue队列多了transfer和tryTransfer方法。 |
| LinedBlockingDeque | 一个由链表结构组成的双向阻塞队列,队列头部和尾部都可以添加和移除元素,多线程并发时,可以将锁的竞争最多降到一半。 |
排队策略要点:
- 同步移交:不会放到队列中,而是等待线程执行它,如果当前线程没有执行,很可能会新开一个线程执行。
- 无界限策略:如果核心线程都在工作,该线程会放在队列中,所以线程数不会超过核心线程数。
- 有界限策略:可以避免资源耗尽,但是一定程度减低了吞吐量。
拒绝策略
拒绝策略是一个接口,设计如下:
1 | public interface RejectedExecutionHandler { |
用户可以通过实现这个接口来定制拒绝策略,也可以选择jdk提供的四种拒绝策略:
| 名称 | 描述 |
|---|---|
| ThreadPoolExecutor.AbortPolicy | 丢弃任务并抛出RejectedExecutionException异常,这个是线程池默认的拒绝策略,在任务不能在提交的时候,抛出异常,及时反馈程序运行状态,如果是比较关键的业务,推荐使用此拒绝策略,这样子在系统不能承载更大的并发量的时候,能够及时通过异常发现。 |
| ThreadPoolExecutor.DiscardPolicy | 丢弃任务,但是不抛出异常,使用此策略,可能会使我们无法发现系统的异常状态。建议是一些无关紧要的业务采用此策略。 |
| ThreadPoolExecutor.DiscardOldestPolisy | 丢弃队列最前面的任务,然后重新提交被拒绝的任务,是否要采用此中拒绝策略,还得根据实际业务是否允许丢弃老的任务来认真衡量。 |
| ThreadPoolExecutor.CallerRunsPolicy | 由调用线程提交任务的线程处理该任务,这种情况是需要让所有任务都执行完毕,那么就适合大量计算的任务类型去执行,多线程仅仅是增大吞吐量的手段,最终必须要让每个任务都执行完毕。如果你的应用程序可以成熟延迟,并且不能丢弃任何一个任务请求的话可以选择这个策略。 |
动态设置线程池参数
自定义线程池参数,也即设置主要参数:corePoolSize、maximumPoolSize、workQueue(队列长度)。
正常的业务环境下,根据当前的需求,更改参数后,要重启服务。如果可以动态修改参数,就可以不用重启服务了(参考美团的实现方案)。
市面上大多数的答案都是要先区分线程池中的任务是IO密集型还是CPU密集型。
如果是CPU密集型,可以把核心线程数设置为服务器核心数+1。
《java并发编程实战》一书中说:即使当计算CPU密集型的线程偶尔由于页缺失故障,或者其他原因而暂停时,这个额外的线程也能保证cpu的时钟周期不会被浪费。
如果是IO密集型,这种任务应用起来,系统会大部分时间处理IO交互,我们可以多配一些线程,通常2N。
参数动态化
动态化线程池的核心设计:
简化线程池配置:线程池构造参数有8个,但是最核心的是三个:corePoolsize、maximumPoolSize、workQueue,它们最大程度的决定了线程池任务分配和线程分配策略。考虑实际应用中我们获取并发性场景:
- 并行执行子任务,提高相应速度,这种情况下,应该使用同步队列,没有什么什么任务应该呗缓存下来,应该立即执行
- 并行执行大批次任务,提升吞吐量。这种情况下。应该使用有界队列。使用队列去缓存大批量的任务,队列容量必须声明,防止任务无限堆积。
所以线程池只需要提供这三个关键参数的配置,并且提供两种队列的选择,就可以满足大部分的业务需求了。
参数可动态修改:为了解决参数不好配,修改参数成本高问题。在java线程池留有高扩展性的基础上,封装线程池,允许线程池监听外部消息,根据消息进行修改配置。
增加线程池的监控:在线程池执行的生命周期添加监控。
JDK原生线程池ThreadPoolExecutor提供了参数的public的setter方法,Jdk允许线程池使用方通过ThreadPoolExecutor的实例来动态设置线程池的核心策略。
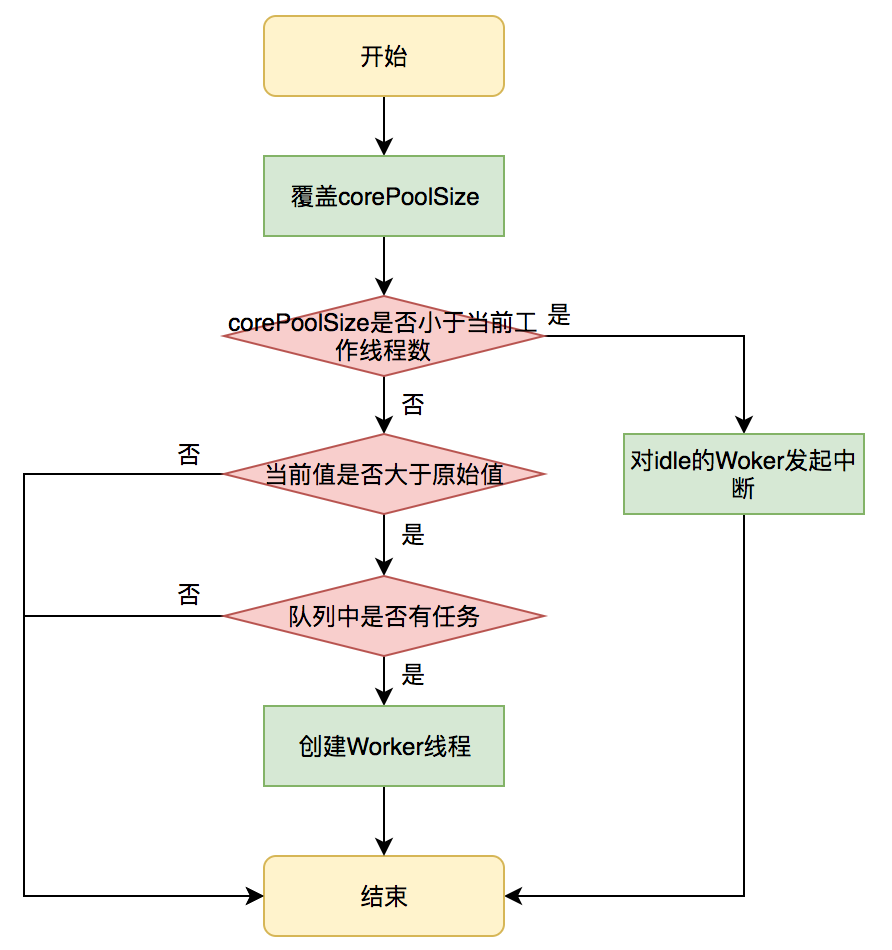
设置CorePoolSize
以setCorePoolSize为例在运行期线程池使用方调用此方法设置corePoolSize之后,线程池会直接覆盖原来的corePoolSize的值,并且基于当前值和原始值的比较结果采取不同的处理策略。
对于当前值小于当前工作线程数的情况,说明有多余的woker线程,此时会向当前idle的worker线程发送中断请求以实现回收,多余的worker在下次idle的时候,也会被回收。
对于当前值大于原始值且当前队列中有等待的任务时,线程池会创建新的worker来执行队列任务。
setCorePoolSize具体流程如下:
设置maximumPoolSize同corePoolSize。
设置队列长度
JDK原生线程池ThreadPoolExecutor的setter方法中没有设置队列长度的setter方法。队列的长度capacity在源码中被定义为了final。
设置长度的思路是:自定义一个队列,将队列的长度capacity的final去掉,并增加setter方法即可。
实例代码
Runnable+ThreadPoolExecutor
MyRunnable.java
1 | import java.util.Date; |
ThreadPoolExecutorDemo.java
1 | import java.util.concurrent.ArrayBlockingQueue; |
Callable+ThreadPoolExecutor
MyCallable.java
1 | import java.util.concurrent.Callable; |
ThreadPoolExecutorDemo.java
1 | import java.util.ArrayList; |
常见问题
线程池被创建后里面有线程吗?如果没有的话,你知道有什么方法对线程池进行预热吗?
线程池被创建后如果没有线程进来,里面是不会有线程的,如果需要预热可以调用方法:prestartAllCoreThreads全部启动、prestartCoreThread启动一个。
核心线程会被回收吗?需要怎么设置?
核心线程默认是不会被回收的,如果需要回收核心线程数,需要调用allowCoreThreadTimeOut(true),allowCoreThreadTimeOut默认值为false。


